
AthenaでCTAS / Insert でパーティション100件超の作成で発生するエラーはIcebergでも発生するのか確認してみた

データ事業本部の笠原です。
Athenaでは、CTASやInsertにてクエリ毎のパーティション作成数は最大100個に制限されています。100パーティションを超える追加が発生した場合は HIVE_TOO_MANY_OPEN_PARTITIONS: Exceeded limit of 100 open writers for partitions/buckets というエラーが発生します。
Icebergテーブルに対しても発生するのか、確認してみました。
結果としてはIcebergテーブルに対しても発生するので、回避方法を合わせて検討しました。
3行まとめ
- Icebergテーブルでも、Athenaクエリの100パーティション超える追加発生時エラーが起こる
- クエリの範囲を絞って100パーティション超える追加が発生しないようにすれば、エラーを回避できる
- 他にGlueジョブやAthenaノートブックのSparkを使えば、エラーを回避できる
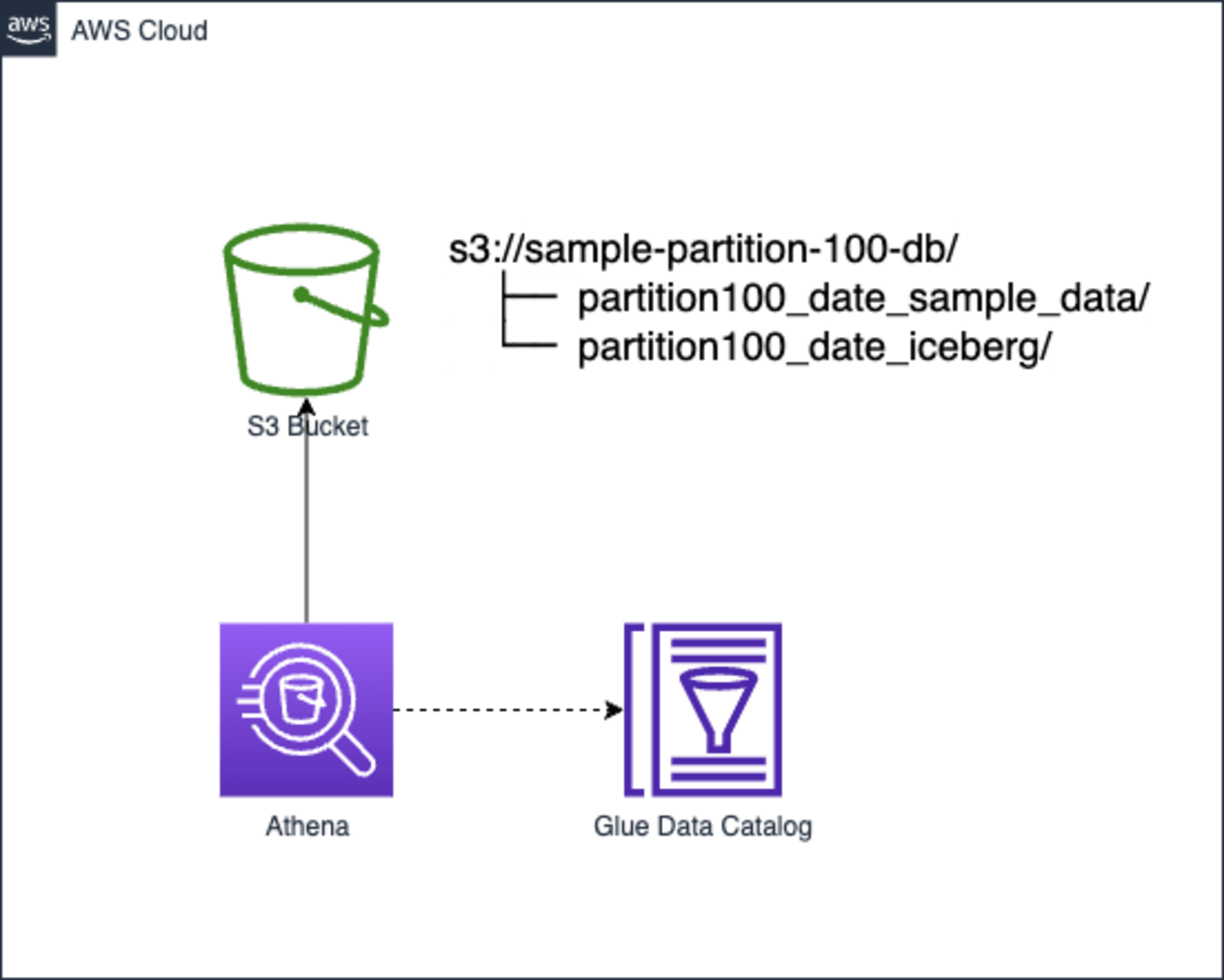
構成
AthenaのSQLクエリは今回AWSマネジメントコンソール上から実行します。
実行時にはGlueカタログを参照します。
Glueカタログで定義されたInput/OutputはいずれもS3バケットのファイルとします。
InputとOutputは同じバケット配下の各パスで分けています。InputはCSVファイルのテーブル、OutputはIcebergテーブルとして事前に定義します。
準備
実際に試す前に、利用するデータとテーブル定義を行います。
入力データファイル作成
今回は試験用にCSVファイルのデータを作成しました。
Icebergテーブルには、日付パーティションで格納したいので、
日付項目となる target_date カラムの値が100超えるだけの行数を適当に生成します。
こんな感じでPythonで作成しました。
データファイル生成コード
import string
import uuid
import datetime
import csv
prefixes = []
chr_lowlist = string.ascii_lowercase
## id の先頭2文字を英小文字の組み合わせ (26*26 = 676) で作る
for chr1 in chr_lowlist:
for chr2 in chr_lowlist:
prefixes.append(chr1 + chr2)
target_date = datetime.date(2023,1,1)
header = ['id', 'uuid', 'target_date']
with open('./partition100_date_sample.csv', 'w') as f:
writer = csv.writer(f)
writer.writerow(header)
for idx, prefix in enumerate(prefixes):
writer.writerow([
f'{prefix}{idx:0=5}',
uuid.uuid4(),
target_date.strftime('%Y-%m-%d'),
])
target_date += datetime.timedelta(days=1)
作成したCSVファイルはこんな感じになります。
id,uuid,target_date
aa00000,c91da6e5-d315-4643-8735-42917648ba44,2023-01-01
ab00001,11e63f6d-7b10-425c-be68-00d02a8c0638,2023-01-02
ac00002,62c05364-44d0-4a7d-8375-409a326b11e8,2023-01-03
ad00003,cde01f0b-5585-4742-a8f2-405a62d9ebc1,2023-01-04
ae00004,95d230e1-7f9d-4fc2-8f0b-85b9398a385c,2023-01-05
af00005,d40425b6-e53c-4d79-b6b0-d3965c4f8636,2023-01-06
...<省略>...
zx00673,7abd5ed6-30c8-4344-aa35-4463eaaf2606,2024-11-04
zy00674,10b0e52c-e7bd-4a80-a829-69b3b13ebb79,2024-11-05
zz00675,2ccecb4c-19c5-4c72-b85c-89f0e3470326,2024-11-06
S3バケット作成
今回のデータファイルを格納するS3バケットを1つ作成しておきます。
AWS CLIでもマネジメントコンソールでも良いので、作りやすい方法で作成しましょう。
また、S3バケット名は適宜変更してください。
aws s3 mb s3://sample-partition-100-db
また、入力データとなるCSVファイルは、この後定義するCSVファイルのGlueテーブルの LOCATION パスに合わせて配置しておきましょう。
aws s3 cp ./partition100_date_sample.csv \
s3://sample-partition-100-db/partition100_date_sample_data/
Glueカタログ定義
まずは、この後定義するテーブルのデータベースをGlueカタログに定義します。
今回はAthenaのクエリエディタで作成しますが、マネジメントコンソールで作成しても構いません。
CREATE DATABASE `sample_partition_100_db`
LOCATION 's3://sample-partition-100-db/'
;
そして、入力となるCSVファイルをGlueカタログにテーブルとして定義します。
CREATE EXTERNAL TABLE `sample_partition_100_db`.`partition100_date_csv` (
id string,
uuid string,
target_date string
)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.OpenCSVSerde'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3://sample-partition-100-db/partition100_date_sample_data'
TBLPROPERTIES (
'classification'='csv',
'columnsOrdered'='false',
'compressionType'='none',
'delimiter'=',',
'skip.header.line.count'='1'
)
;
続いて、出力先となるIcebergテーブルを定義します。
TBLPROPERTIES にて、 'table_type'='ICEBERG' を指定することで、Icebergテーブルとして振舞います。
また、日付カラム target_date を日別にパーティションを組むようにします。
CREATE TABLE `sample_partition_100_db`.`partition100_date_iceberg` (
id string,
uuid string,
target_date date
)
PARTITIONED BY (day(target_date))
LOCATION 's3://sample-partition-100-db/partition100_date_iceberg'
TBLPROPERTIES (
'table_type'='ICEBERG'
)
;
これで準備ができました。
Athenaでやってみる
IcebergテーブルにPartitionが100を超えるInsert処理を実行します。
Athenaクエリエディタで以下のSQLを実行してみます。
INSERT INTO partition100_date_iceberg
SELECT id, uuid, CAST(target_date AS date)
FROM partition100_date_csv
;
すると、以下のようなエラーが表示されるはずです。
ICEBERG_TOO_MANY_OPEN_PARTITIONS: Exceeded limit of 100 open writers for partitions.
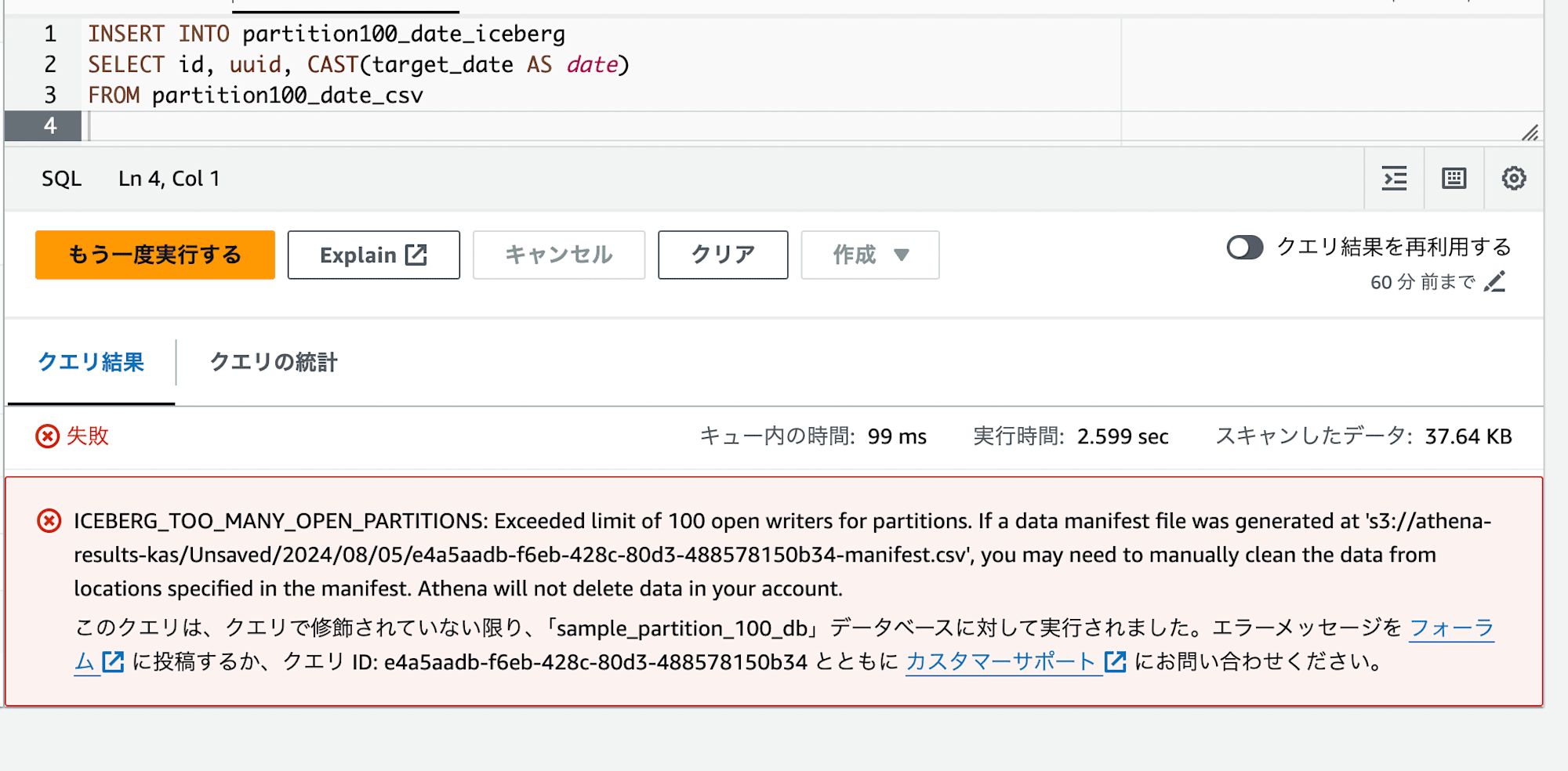
Icebergテーブルに対しても、100パーティションを超える追加の際にエラーが発生することがわかりました。
ついでに、CTASでも同様のエラーが発生するか確認します。
Icebergテーブルをdropした後、
以下のSQLを実行します。
create table partition100_date_iceberg
with (
table_type = 'ICEBERG',
is_external = false,
location = 's3://sample-partition-100-db/partition100_date_iceberg/',
partitioning = ARRAY[ 'day(target_date)' ]
) as
select id, uuid, cast(target_date as date) as target_date
from partition100_date_csv
;
実行すると、同様のエラーが発生することがわかります。
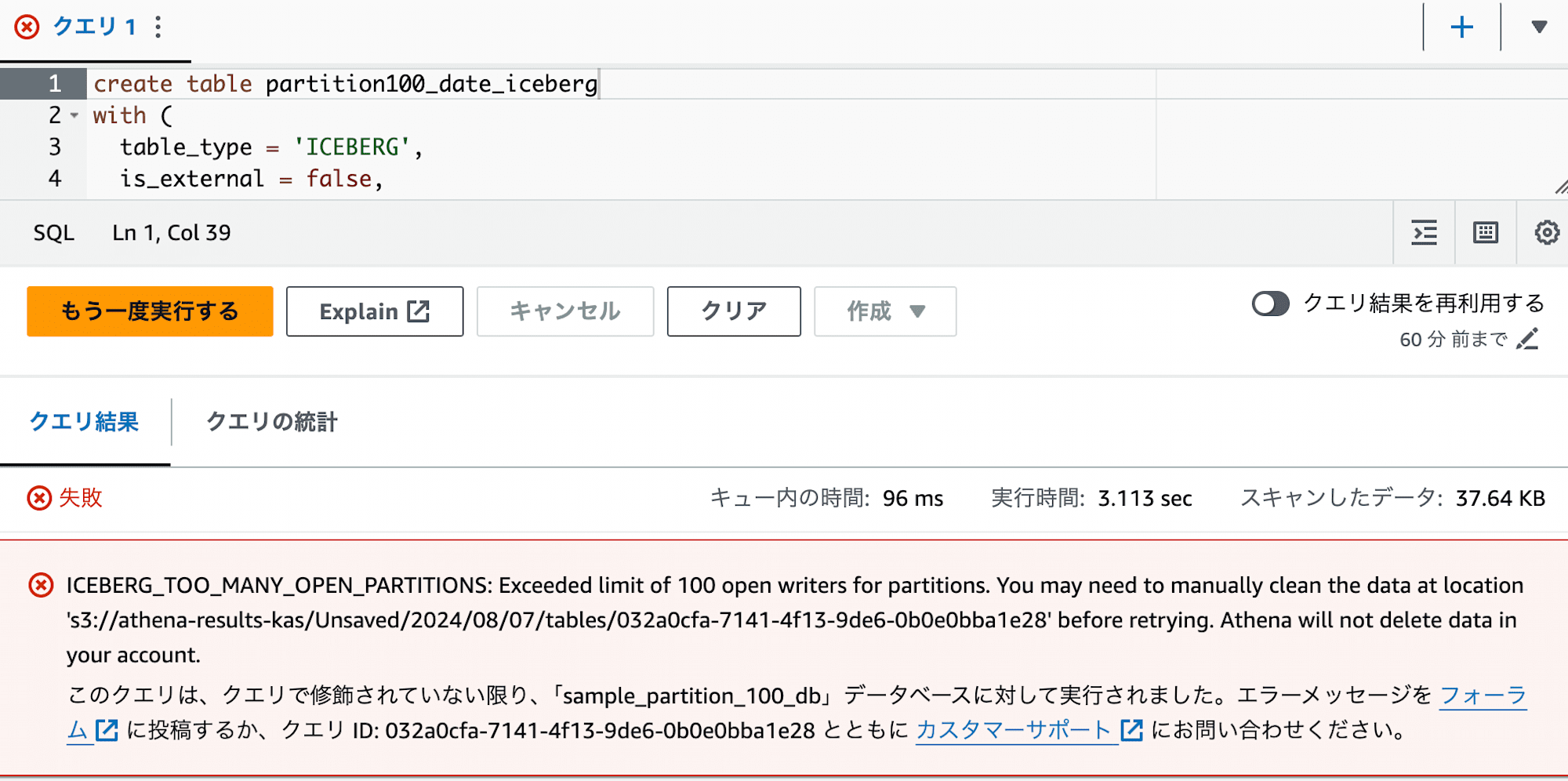
対処法
パーティションが100個を超える新規作成を実施する必要がある場合の対処法を考えてみます。
1. 100個を超えないようにクエリを分割する
これはAWSのドキュメントでも案内されている方法です。
パーティションを100個を超えないように新規作成するように範囲を指定して実行します。
例えば、先ほどの INSERT クエリは以下のように分けて実行します。
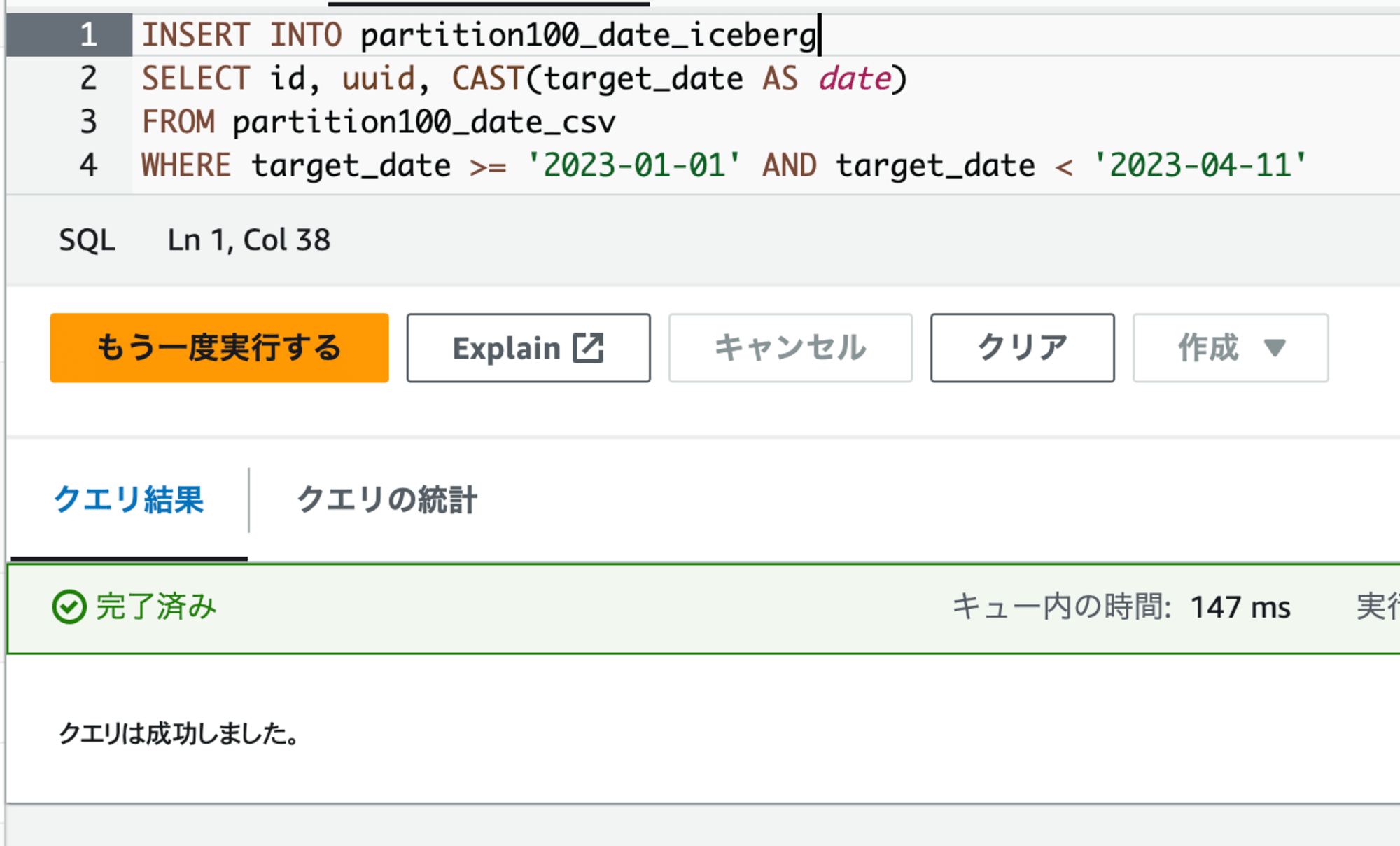
INSERT INTO partition100_date_iceberg
SELECT id, uuid, CAST(target_date AS date)
FROM partition100_date_csv
WHERE target_date >= '2023-01-01' AND target_date < '2023-04-11'
;
INSERT INTO partition100_date_iceberg
SELECT id, uuid, CAST(target_date AS date)
FROM partition100_date_csv
WHERE target_date >= '2023-04-11' AND target_date < '2023-07-20'
;
INSERT INTO partition100_date_iceberg
SELECT id, uuid, CAST(target_date AS date)
FROM partition100_date_csv
WHERE target_date >= '2023-07-20' AND target_date < '2023-10-28'
;
INSERT INTO partition100_date_iceberg
SELECT id, uuid, CAST(target_date AS date)
FROM partition100_date_csv
WHERE target_date >= '2023-10-28' AND target_date < '2024-02-05'
;
INSERT INTO partition100_date_iceberg
SELECT id, uuid, CAST(target_date AS date)
FROM partition100_date_csv
WHERE target_date >= '2024-02-05' AND target_date < '2024-05-15'
;
INSERT INTO partition100_date_iceberg
SELECT id, uuid, CAST(target_date AS date)
FROM partition100_date_csv
WHERE target_date >= '2024-05-15' AND target_date < '2024-08-23'
;
INSERT INTO partition100_date_iceberg
SELECT id, uuid, CAST(target_date AS date)
FROM partition100_date_csv
WHERE target_date >= '2024-08-23' AND target_date < '2024-12-01'
;
上記のクエリはパーティションを新規に100個まで作られる範囲毎に分けています。
このようにすることで、必要なデータが無事Insertされました。
2. Glueジョブを使う
初回連携時にデータを一気に投入する場合等、
件数が多い場合等クエリを分割して実行することが困難な場合もあると思います。
その場合はAthenaクエリではなく、例えばGlueジョブを使うと一気に投入することができます。
例えばVisual ETLでジョブを作成すると、以下のようになります。
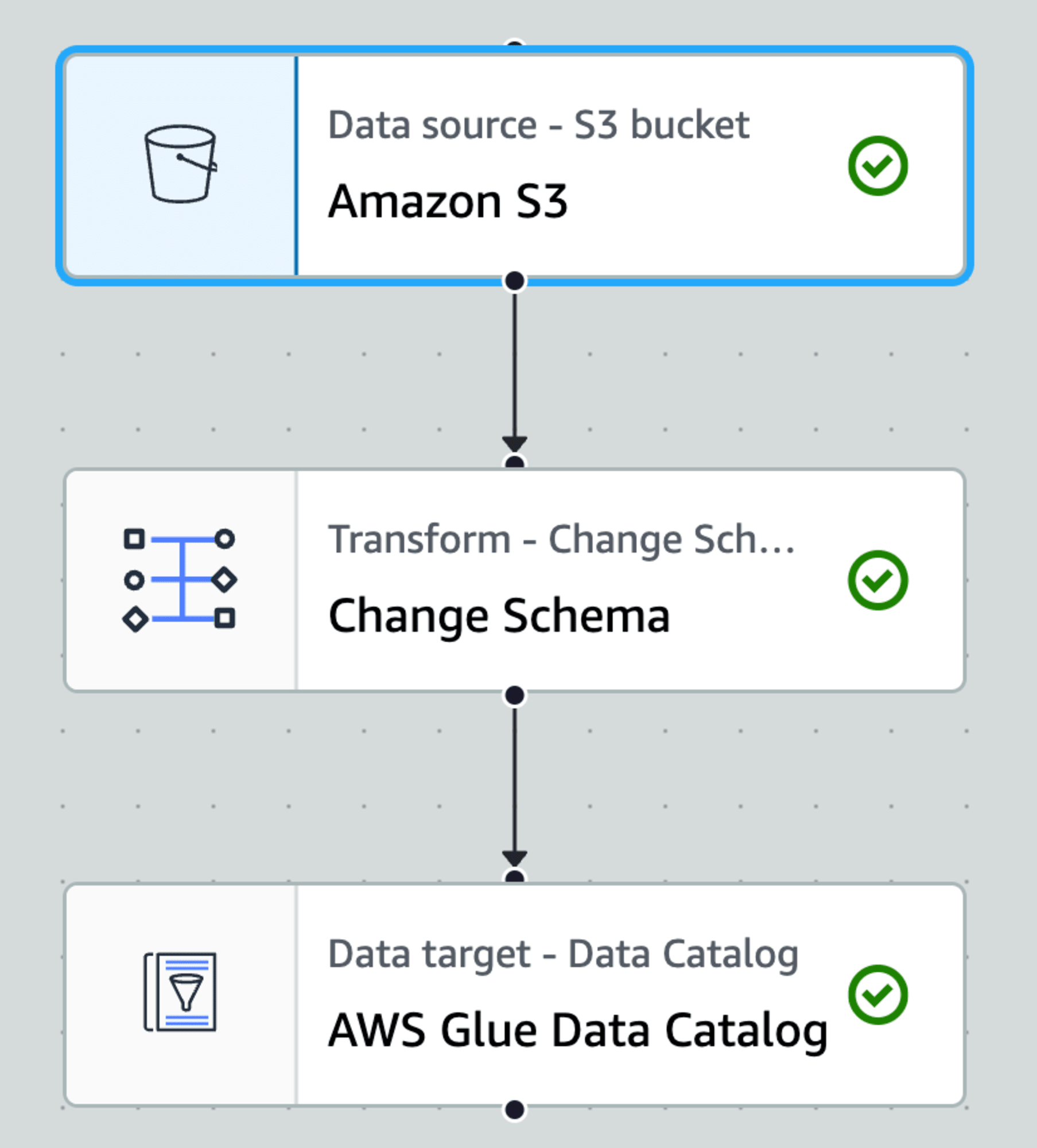
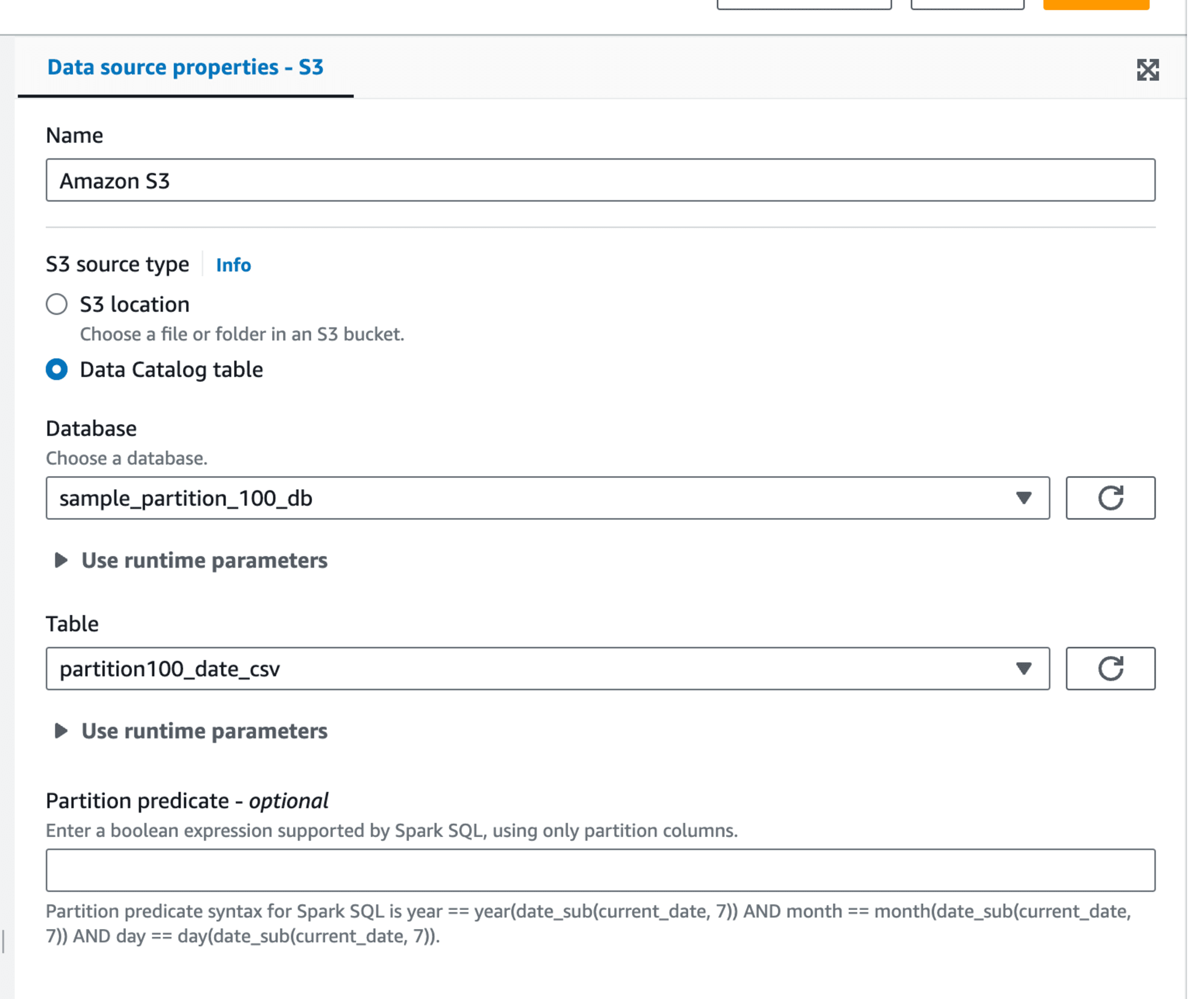
入力はs3から取得。Glue Data CatalogのCSVテーブルを使っておきます。
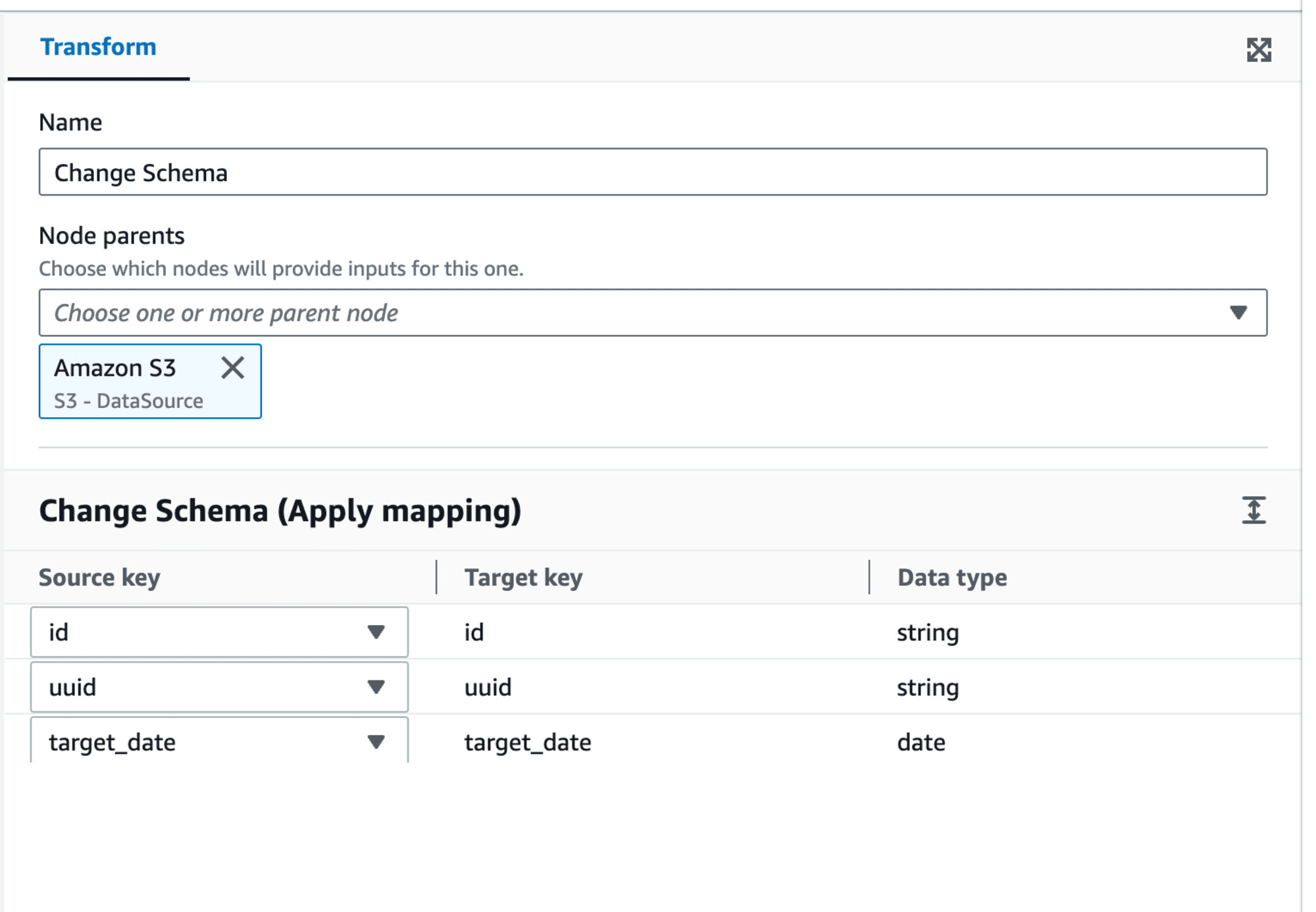
途中、date型への変換用のtransformを入れてます。
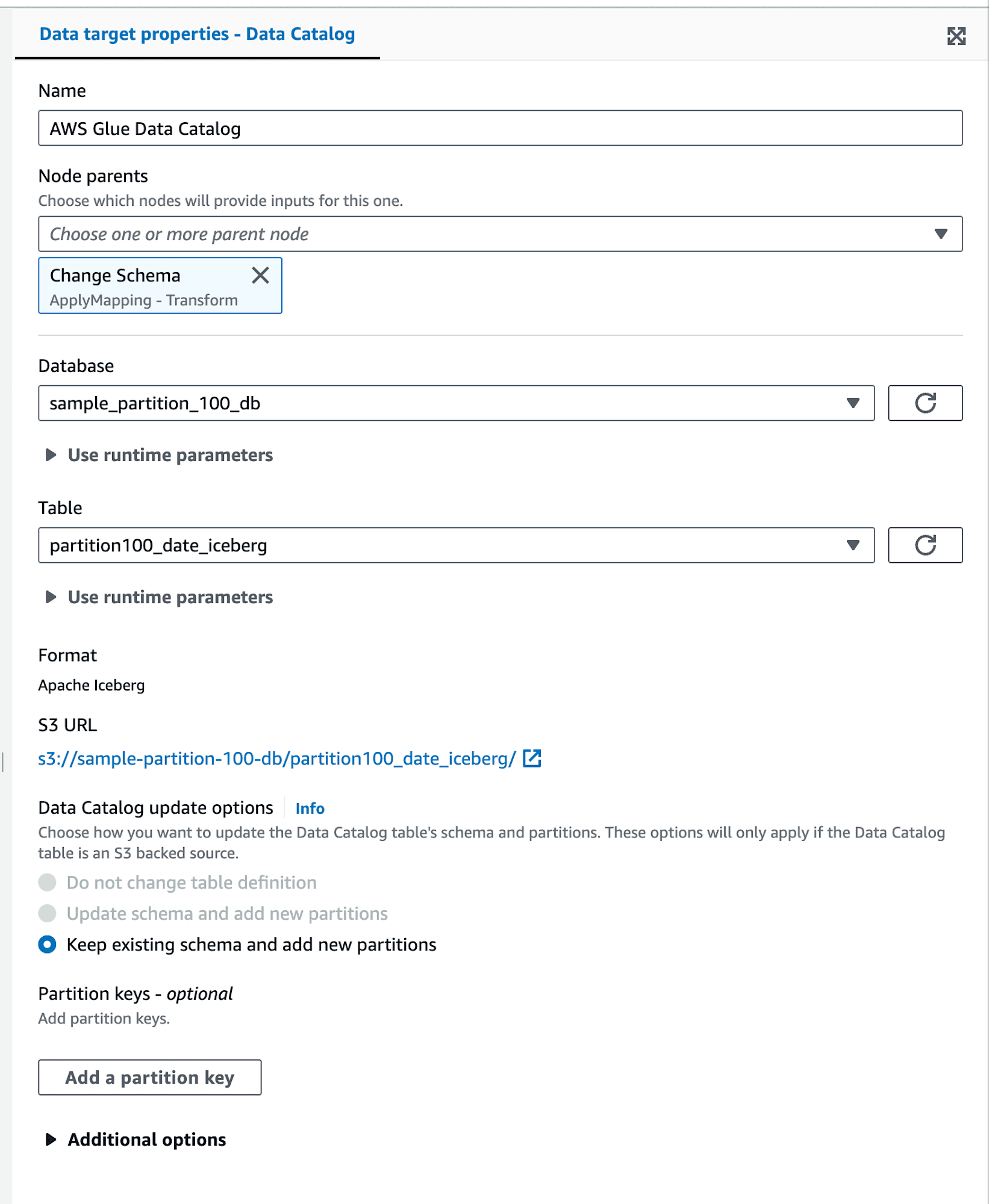
出力はGlue Data CatalogのIcebergテーブルを指定します。
参考までに、Visual ETLで生成されたコードの内容は以下のとおりです。
Visual ETLで生成されたコード
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
# Script generated for node Amazon S3
AmazonS3_node1719451067133 = glueContext.create_dynamic_frame.from_catalog(database="sample_partition_100_db", table_name="partition100_date_csv", transformation_ctx="AmazonS3_node1719451067133")
# Script generated for node Change Schema
ChangeSchema_node1719461645275 = ApplyMapping.apply(frame=AmazonS3_node1719451067133, mappings=[("id", "string", "id", "string"), ("uuid", "string", "uuid", "string"), ("target_date", "string", "target_date", "date")], transformation_ctx="ChangeSchema_node1719461645275")
# Script generated for node AWS Glue Data Catalog
AWSGlueDataCatalog_node1719451091694_df = ChangeSchema_node1719461645275.toDF()
AWSGlueDataCatalog_node1719451091694 = glueContext.write_data_frame.from_catalog(frame=AWSGlueDataCatalog_node1719451091694_df, database="sample_partition_100_db", table_name="partition100_date_iceberg", additional_options={})
job.commit()
3. AthenaのSparkノートブックを使う
他にも、AthenaのクエリではなくSparkノートブックを使う方法があります。
Athenaのノートブックを新規作成しましょう。
その際、Sparkに対応するワークグループがなければ、ワークグループから作成しましょう。
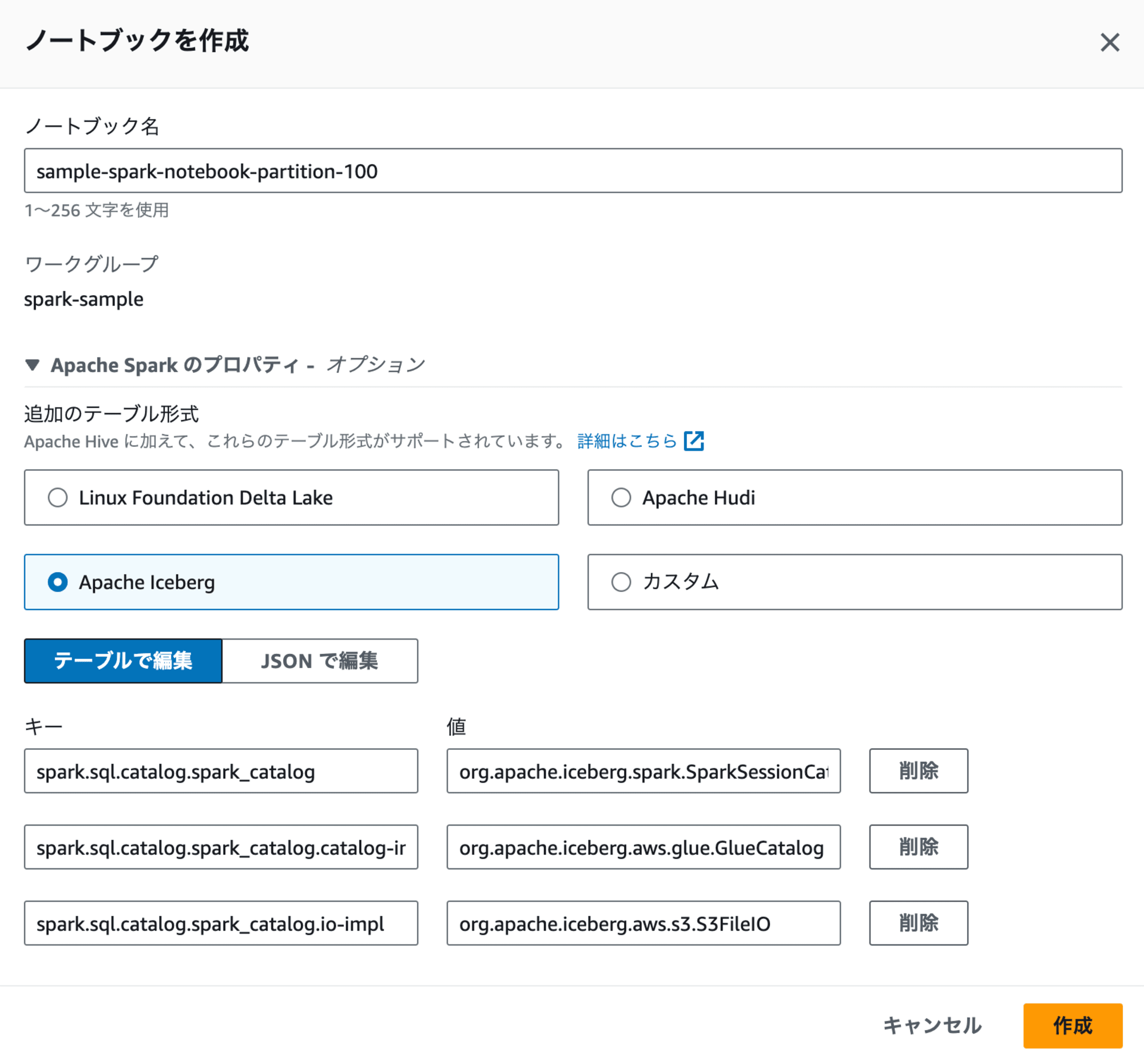
ノートブック作成時には、「Apache Sparkのプロパティ」にて「Apache Iceberg」を選択しましょう。選択時に表示されるキーと値はデフォルトのままでOKです。
ノートブック起動したら、以下のコードを実行します。
spark.sql('''
INSERT INTO sample_partition_100_db.partition100_date_iceberg
SELECT id, uuid, CAST(target_date AS date)
FROM sample_partition_100_db.partition100_date_csv
WHERE id <> 'id'
'''
)
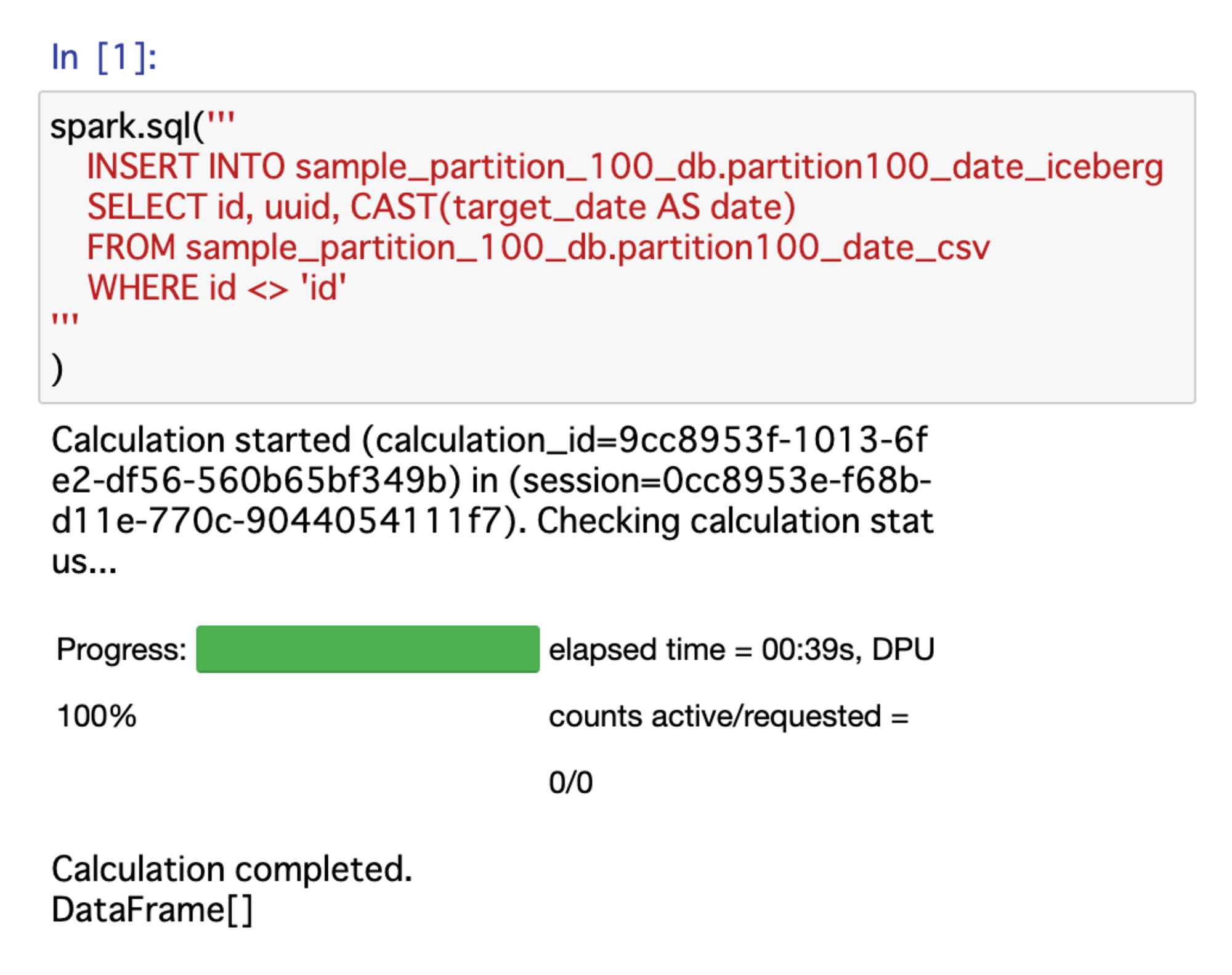
この方法でも、新規作成パーティションが100個を超えるデータのInsertは問題なく実行可能です。
ちなみに、入力テーブル partition100_date_csv に設定している、最初のヘッダ行1行を無視する設定 'skip.header.line.count'='1' が、Athena Sparkでの spark.sql() 実行時にはうまく有効化してくれないようです。
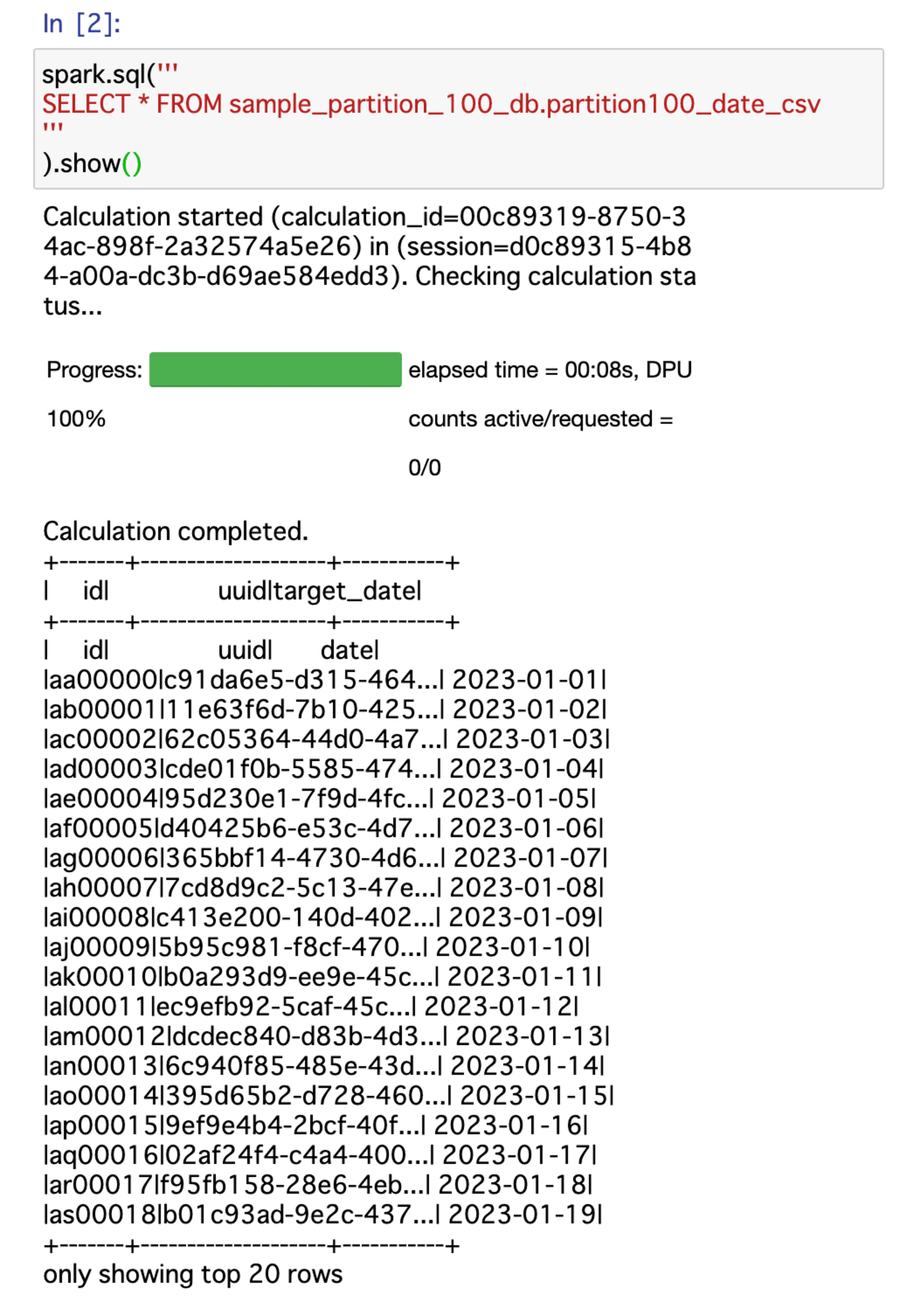
そのため、今回は WHERE id <> 'id' としてカラム名が入っている行を除くように条件を付与しています。
まとめ
Icebergテーブルでも、Athenaクエリの100パーティション超える追加発生時エラーが起こることがわかりました。
クエリの範囲を絞って100パーティション超える追加が発生しないようにすれば、エラーを回避できます。
また、GlueジョブやAthenaノートブックのSparkを使えば、エラーを回避できます。
この記事が誰かのお役に立てることができれば幸いです。






